
DAG 방식의 Workflow 관리 도구 간략 체험기
유저 기기에서부터 머신러닝 모델까지 데이터가 도달하기 위해 발생해야하는 수많은 처리 과정들을 Jenkins와 같은 CI/CD 툴 내에서 해결하기에는 그 파이프라인의 복잡도가 조금만 높아지더라도 직관성이 떨어지게 됩니다. 그래서 workflow 내의 task들을 DAG (Directed Acyclic Graph)를 통해 관리해 직관성을 높여주는 툴들이 2015년 경부터 등장하기 시작했습니다.
모든 툴 들을 실제로 사용해본 것은 아니지만, 여러 workflow 관리 툴의 docs와 튜토리얼을 진행해보며 느낀 점 등을 간략하게 정리해보았습니다. (그렇기 때문에 틀린 점이 많을 수도 있으니 지적해주시면 감사드리겠습니다.)
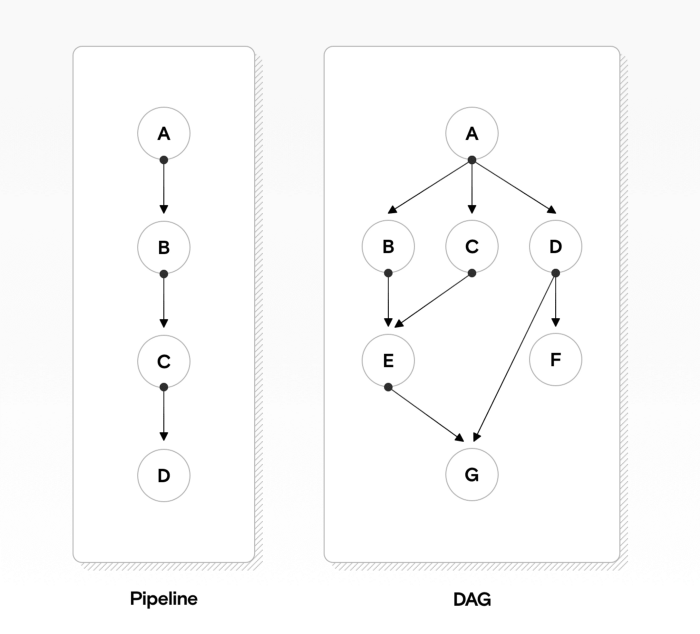
위 그림 왼쪽과 같은 간단한 파이프라인은 CI/CD 툴에서도 간편하게 구현 가능합니다. 그러나 오른쪽과 같이 그 복잡도가 조금 더 증가하고, 특히 예외처리나 특정 실행조건까지 추가되는 경우에는 분명 한계가 존재하기 때문에, 이런 workflow 관리를 DAG 방식으로 처리하는 것이 보편화되어 왔습니다.
초창기에는 빅데이터 시대를 대표하는 하둡 프레임워크의 데이터 처리 과정을 효율적으로 관리하기 위해 Data Pipeline 관리를 중점으로 하는 DAG workflow 툴들이 등장했다면 (Airflow, Luigi), 요즘은 ML이 서비스에 적용되는 사례가 많아지면서 (MLaaS) ML 데이터 준비 + 모델 학습, 관리 + 서빙 등의 과정을 관리하는, MLOps 툴들이 핫해지고 있습니다.
툴 간 Github Star 비교

(출처: https://towardsdatascience.com/airflow-vs-luigi-vs-argo-vs-mlflow-vs-kubeflow-b3785dd1ed0c)
Luigi는 spotify에서, Airflow는 airbnb에서 개발한 워크플로우 관리 툴입니다. 앞의 2개가 Data pipeline 구축에 중점이 맞춰져 있다면, 뒤쪽에 등장하는 Kubeflow, MLflow, Argo, Prefect는 MLOps 또는 클라우드 환경에 조금 더 무게가 실려있는 툴들입니다. 이외에도 넷플릭스에서 개발한 Metaflow, 그리고 dagster 등 까지, 다양한 툴들이 각자의 장점을 내세우며 입지를 넓혀가고 있습니다.
1. Airflow
에어플로우는 현재 재직중인 회사에서도 활발하게 사용하고 있습니다. 예전엔 Executor로 Celery를 사용하는게 일반적이었으나, 현재는 KubernetesExecutor를 통해 kubernetes 클러스터에 컨테이너 기반으로 task 지휘를 하는 비중이 높아지고 있는 것 같습니다. 내부적으로 k8s API를 사용하기 때문에, kubeconfig 파일 등을 통해 쿠버네티스 클러스터와 잘 연동만 해준다면, 여러 클러스터를 넘나드며 태스크 관리가 가능하다는 것이 큰 장점으로 느껴졌습니다.
타 툴에 비해서 상당히 기능이 많기 때문에 긍정적인 점도 있지만, 운영측면에서 생각보다 크고 작은 이슈들이 많이 발생하는 편이었습니다. 특히, 수행할 잡이 그닥 많은 수준이 아닌데도, task를 관리하는 scheduler의 응답시간이 상당히 느렸고, 단일 스케줄러 한계로 인해 실무에서 scheduler down time에 일제히 잡들이 밀리는 일, 그리고 SPOF 문제도 종종 발생했습니다.
다만, 최근에 버전 2를 release하면서 scheduler 문제를 특히 많이 개선했다고 하고, (아래 벤치마크, 출처: Astronomer Blog: airflow 2.0 scheduler)
| Scenario | DAG shape | 1.10.10 Total Task Lag | 2.0 beta Total Task Lag | Speedup |
|---|---|---|---|---|
| 100 DAG files, 1 DAG per file, 10 Tasks per DAG | Linear | 200 seconds | 11.6 seconds | 17 times |
| 10 DAG files, 1 DAG per file, 100 Tasks per DAG | Linear | 144 seconds | 14.3 seconds | 10 times |
| 10 DAG files, 10 DAGs per file, 10 Tasks per DAG | Binary Tree | 200 seconds | 12 seconds | 16 times |
Google Cloud Platform에서 airflow를 솔루션으로 제공하기도 하면서 컨트리뷰션도 한다는 점, 사용자 층이 많다는 점에서 앞으로도 발전 가능성이 있다고 보이기 때문에 Data pipeline 구성 관점에서는 나머지 툴들에 비해 가장 우선적으로 사용을 고려해봐야한다고 개인적으로 생각합니다..
다만, ML 파이프라이닝 특화 기능은 다른 툴에 비해 아직은 부족한 상태라고 보입니다. jupyter notebook 등은 papermill을 통한 연동 수준으로 보고서 생성 정도가 가능합니다. 다만, Tensorflow Extended에서 airflow operator를 제공한다거나 가이드를 제공하는 등, 꾸준히 개선이 되고 있는 중인 것으로 보입니다.
2. Luigi
Spotify에서 개발한 workflow 개발 툴로, 현재 많이 활용되는 툴 중에서는 가장 오래된 툴입니다. Long-running batch process, 특히 하둡관련 작업을 트래킹하고 에러, 예외 처리 등을 처리하는데 강점이 있다고 합니다.
hadoop job들만 관리하는 등, 특정 목적 한정으로는 luigi가 airflow에 비해 적절할 수도 있지만, airflow와 마찬가지로 luigi 전용 문법을 배우는데 시간을 꽤 써야한다는 점에서, 굳이 luigi를 꼭 사용해야하는 이유를 찾지는 못했기 때문에 상세히 알아보지는 않았습니다.
일단 UI가 맘에 안들었습니다
airflow와 마찬가지로 data pipeline 쪽에 초점이 맞춰져있고, ML 특화 기능은 거의 지원하지 않습니다.
3. Metaflow
넷플릭스에서 데이터 사이언티스트가, 데이터 모델링 이외에 마주하는 실제적인 개발 이슈들 (데이터 파이프라인 + 배포 + 에러 관제 등) 에서 경험하는 부담들을 덜어주기 위해 고안한 플랫폼이라고 합니다.
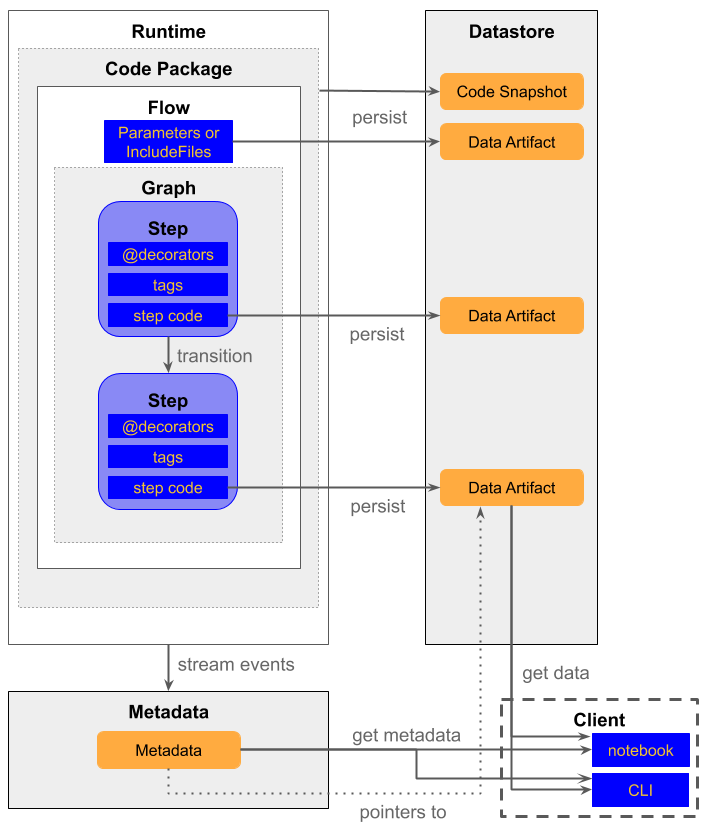
airflow나 luigi와 마찬가지로 하나의 파이썬 스크립트가 DAG의 역할을 합니다. 그리고, Metaflow에서만 사용되는 전용 문법이 별로 없기 때문에 학습 난이도가 낮고, 파이써닉한 DAG를 작성할 수 있다는 점이 매력적으로 다가왔습니다.
다만, AWS 내 사용을 전제로 만들었다는 느낌이 강하게 든 플랫폼입니다. 각 스탭에서 생성되는 산출물들은 Datastore를 통해 관리되고, 이는 향후 데이터 사이언티스트들이 아래와 같이 쉽게 산출물을 분석할 수 있게 해주는 역할을 해줍니다.
그런데, 이 Datastore는 사실상 s3 (AWS 파일 시스템)만 사용할 수 있다는 점이 한계점입니다. 다른 파일 시스템을 사용하고 싶은 경우에는 추상화 클래스에 정의된 함수들을 직접 구현해내 사용할 수 있지만, 인프라 조직이 아닌 개발 조직의 입장에서는 공수가 상당히 많이 드는 작업일 것이라 생각됩니다.
또한, AWS를 사용하지 않고서는 Scale out도 거의 불가능하다는 단점이 있습니다. 각 Step이 single machine 내에서만 실행되는 것으로 전제된다면, 다중 태스크 관리를 위한 data pipeline 툴로 사용하기는 어려워지는데, 이 Metaflow는 scale-up, out 방안으로 AWS Batch를 사용하도록 합니다.
사용해본 적이 없어 상세 기능은 모르지만, AWS Batch는 필요한 자원을 명시하여 스크립트나 개발 환경등을 제공하면, 해당 스크립트가 돌아가는 시간 동안만큼 사용한 자원에 대해서만 비용청구가 이루어져, 합리적인 자원 사용이 가능한 시스템인 것으로 보입니다.
사실 사내에서는 AWS를 사용하지 않기 때문에 마찬가지로 고려하지 않은 플랫폼이지만, 참고할 점이 많은 프로젝트라고 느껴졌습니다. 특히, airflow의 경우는 태스크간 산출물 전달, 관리가 오로지 DB를 통해서만 이루어지는데(XCom), XCom Backend 등으로 Metaflow의 Datastore과 같이 HDFS같은 파일 시스템을 지원한다면.. 얼마나 편할까 하는 생각이 들었습니다.
4. prefect
자동화, 테스트, 배포 간편화가 모토인 것으로 보입니다. 다만, Prefect Core (아래의 엔진)만 오픈소스이고, Web UI 등은 Prefect Cloud 등으로 제공이 되는데, 이는 오픈소스가 아니며 매월 돈을 지불해야하는 것으로 보입니다. 심지어 코어 라이센스도 일반적인 라이센스가 아닌 자체 정의 라이센스이기 때문에, 실 사용에 제약이 많아보이는 프로젝트였습니다.

컴포넌트들이 직관적이지 않은데.. Apollo가 유저가 접하는 endpoint의 이름이고, Towel이 Scheduler, Zombie killer의 역할을 한다고 합니다. 유저는 Apollo 컴포넌트의 기능만 알아두면, 나머지는 백엔드에서 알아서 한다는 점을 강점으로 내세웁니다.
독특한 점은 Flow(DAG)의 버저닝을 지원한다는 점이고, Executor가 LocalExecutor (단순 스크립트 실행), LocalDaskOperator(Dask 백엔드를 이용해 싱글머신 내 병렬처리), DaskExecutor(Dask Distributed 엔진을 이용해 클러스터 내 분산처리)가 존재한다는 점이었습니다. 분산/병렬 어플리케이션을 직접 디자인한 다음에 Flow에 포함시킬 수 있다는 강점이 매력적으로 느껴졌습니다.
분석을 위해 각각의 task에서 생성되는 산출물을 어떻게 serialize할 것인지 취사 선택할 수 있다는 것도 장점으로 느껴졌습니다. prefect DB에 serialize된 객체를 직접 저장할 수도 있고(airflow stype), DB뿐만 아니라 gcs, aws, local file system 등과 간편 연동할 수 있도록 사전 구현이 되어있습니다.
5. Argo Workflow
Cloud Native Computing Foundation의 인큐베이팅 프로젝트입니다. Argo CD는 GitOps를 통해 helm chart 등의 배포, 클러스터 배포 이력 관리 등의 역할을 한다면, Argo Workflow는 말 그대로 Workflow 관리의 역할을 수행합니다. Argo CD와 마찬가지로, 쿠버네티스 클러스터에서 컨테이너 기반의 워크플로우를 만드는 것을 전제로 하고 있으며, GitOps를 통한 workflow 관리를 할 수 있습니다.
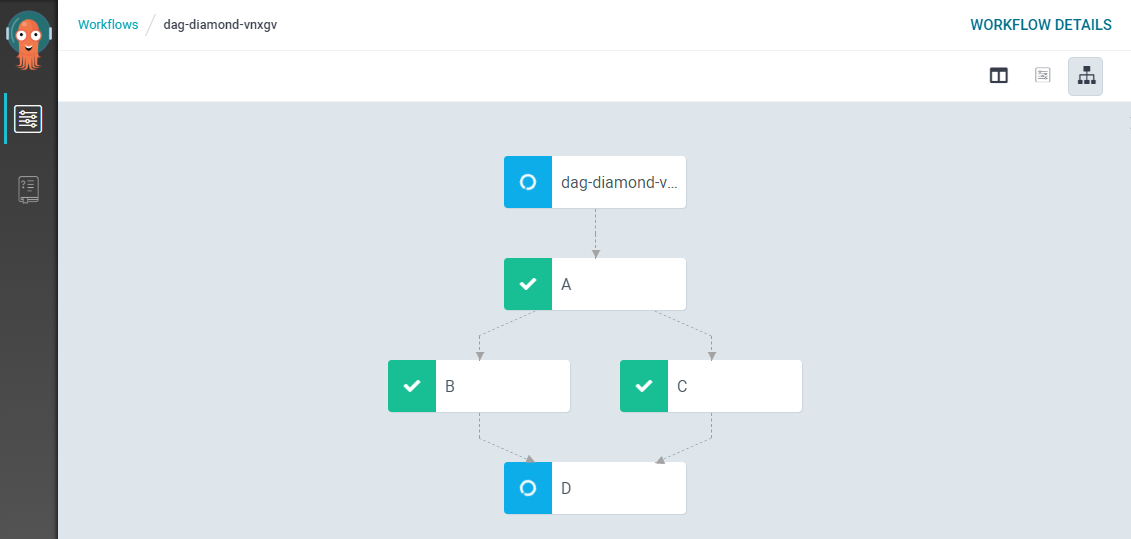
컨테이너 기반의 KubernetesExecutor를 사용하는 airflow와는 상당히 유사해보일 수도 있지만, airflow는 자체 구축된 scheduler를 사용하는 반면, Argo workflow는 scheduler로 쿠버네티스 코어인 kube-scheduler를 사용하고, 메타데이터 DB는 airflow는 PostgresSQL이나 MySQL를 사용하는 방면, Argo workflow는 etcd (쿠버네티스 내장 키-밸류 저장소)하는 등 쿠버네티스 코어를 구성하고 있는 컴포넌트를 직접 사용한다는 특징이 있습니다. (쿠버네티스 컴포넌트 목록).
다만, DAG를 yaml로 정의해야 하는 점은 살짝 아쉬운 점이고, MLOps에서 거의 항상 등장하는 Artifacts 공유 (airflow-XCOM, Metaflow-DataStore 등..) 등의 기능이 존재하긴 하지만, 간편히 전달할 수 있는 것은 아닌 것으로 보여 편하지는 않겠다는 생각이 들었습니다. (artifacts 공유 example). 마찬가지로, dag가 너무 복잡해지는 경우에서도, yaml로 저걸 다 짤 수 있을까.. 라는 의문점이 남기는 합니다.
쿠버네티스 컴포넌트를 활용하기 때문에 로깅, 이벤트 등도 airflow scheduler 구조를 이해하는 것과 같이 별도 학습 비용이 드는 것이 아닌 점도 장점으로 다가왔습니다.
참고: yaml 예제들
6. Kubeflow
구글 오픈소스 진영에서 개발한 MLOps 툴입니다. 처음에는 Argo Workflow와 vs 관계로 생각했는데, Argo를 백엔드로 사용해서 돌아갑니다.
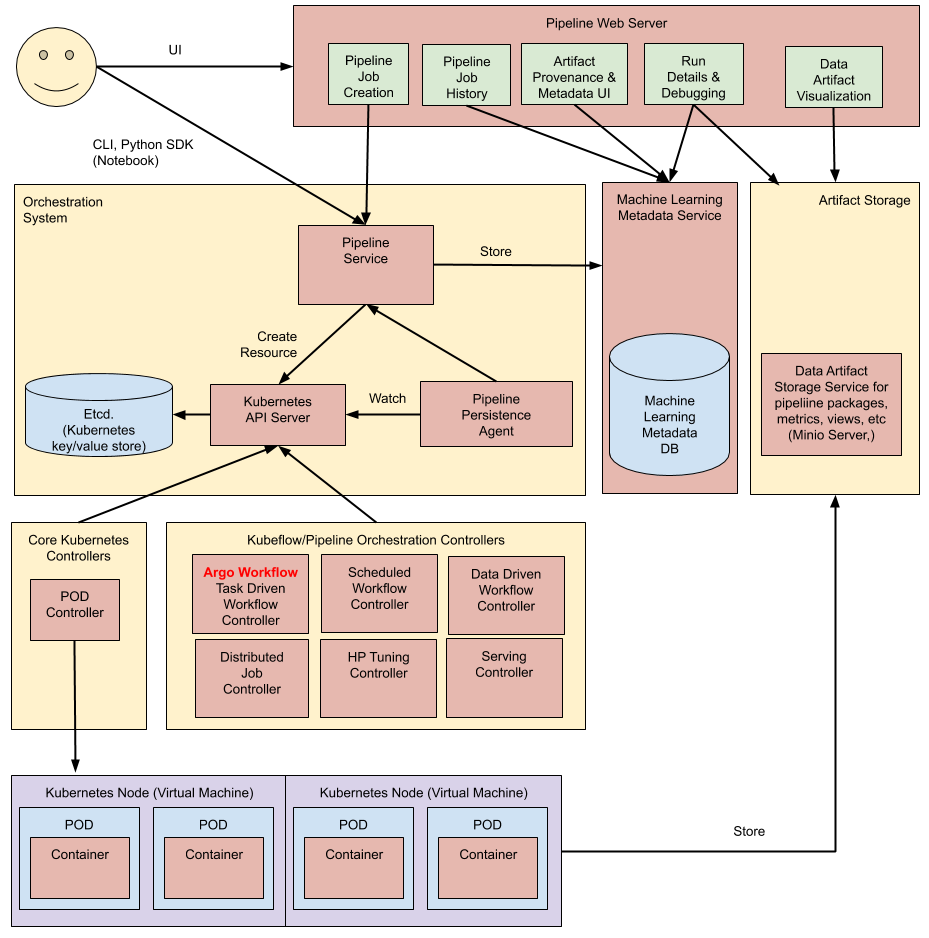
Argo가 일반적인 워크플로우를 위해 디자인된 플랫폼이기 때문에, 위에서 이야기한대로 MLOps에 적용하기는 살짝 아쉬운 점이 많습니다. 그런 점을 강화한 MLOps 툴이라 요약할 수 있을 것 같습니다.
예를 들면, workflow의 학습 단계에서 학습과정/metric 등을 모니터링 한다거나, Tensorboard를 플랫폼 내에서 띄운다거나, 산출물을 주피터로 직접 확인해본다거나.. 얼핏 보기에 매력적인 기능들이 많아보입니다.
jupyter lab과의 연동성이 상당히 좋고.. (아예 주피터로 workflow까지 관리할 수 있는 것 같아 보입니다!) 모델 버전 등 ML Metadata 관리 기능도 있는 것으로 보입니다. 특히, 구글 프로젝트이니만큼 tensorflow serving, extended, board 등과 같은 텐서플로우 생태계와의 연동성이 좋은 ML플랫폼으로 보입니다.
다만, 도큐먼트가 상당히 불친절하게 느껴졌고, kubeflow python API를 통한 DAG 작성이 가능하긴 한데, 이게 argo yaml을 생성해주는 모양입니다. 구조 특성상 kubernetes 배포 옵션까지 고려해야하기 때문에 학습 비용이 많이 들 것 같다는 느낌이 들었습니다.
# 예시
import kfp
@kfp.components.func_to_container_op
def print_func(param: int):
print(str(param))
@kfp.components.func_to_container_op
def list_func(param: int) -> list:
return list(range(param))
@kfp.dsl.pipeline(name='pipeline')
def pipeline(param: int):
list_func_op = list_func(param)
with kfp.dsl.ParallelFor(list_func_op.output) as param:
print_func(param)
if __name__ == '__main__':
artifact_location = ArtifactLocation.s3(
bucket="__argo_bucket_name__",
endpoint="s3.amazonaws.com",
region="us-west-2",
insecure = False,
access_key_secret=V1SecretKeySelector(name="__secret_name__", key="aws-access-key-id"),
secret_key_secret=V1SecretKeySelector(name="__secret_name__", key="aws-secret-access-key"))
# config pipeline level artifact location
conf = dsl.PipelineConf()
conf = conf.set_artifact_location(artifact_location)
workflow_dict = kfp.compiler.Compiler()._create_workflow(pipeline,pipeline_conf=conf)
workflow_dict['metadata']['namespace'] = "default"
del workflow_dict['spec']['serviceAccountName']
kfp.compiler.Compiler._write_workflow(workflow_dict, "pipe.yaml")
7. MLflow
Kubeflow가 구글 진영 프로젝트라면, MLflow는 데이터브릭스 진영 프로젝트입니다. 스파크 개발팀이 참여했다고 합니다. Kubeflow가 Argo를 기반으로 data pipeline부터 머신러닝 모델 관리까지 다 커버가 가능한 프로젝트라면, MLflow는 순전히 머신러닝 모델 관리/배포에 초점이 맞추어져 있는 플랫폼입니다.

앞단에 airflow와 같은 data pipeline 툴을 두고, mlflow를 붙여 MLPlatform을 구성하는 사례가 많아 보입니다. Google Cloud next 19 세션에서는 airflow로 data pipeline을 구성하고, kubeflow로 MLOps를 진행하는 경우도 소개합니다. (출처: 변성윤님 블로그 - google-next19-review)
또한, MLflow는 모델을 저장/버저닝/관리 하는 관점에서 상당한 강점을 지니고 있기 때문에, 이를 Kubeflow와 통합해 사용하는 경우가 소개되기도 합니다. (출처: medium - ML with Kubeflow and MLflow)
파이프라이닝 툴이 아니기 때문에… DAG는 없으나, 상당히 간편한 방식으로 모델 관리를 진행할 수 있다. (keras model 샘플 스크립트)
(덧: 세션에서 소개된 적이 있기는 한 것 같습니다. 사용해보신 분들의 후기를 듣고 싶습니다! (참고: MLFlow dag 사용 영상)
주요 기능은 다음과 같습니다.
- 1) MLflow Tracking
- 파라미터와 결과를 비교하기 위해 실험 결과를 저장
- 2) MLflow Projects
- 머신러닝 코드를 재사용 가능하고 재현 가능한 형태로 포장
- 포장된 형태를 다른 데이터 사이언티스트가 사용하거나 프로덕션에 반영
- 3) MLflow Models
- 다양한 ML 라이브러리에서 모델을 관리하고 배포, Serving, 추론

서베이 후기
개발과는 큰 관련이 없지만, 플랫폼 기업 (Google, Microsoft (Databricks)) 등에서 오픈 소스로 DevOps 툴을 공개하고, 이를 자기네 클라우드 서비스 내에서 사용하는 경우, 사용이 편리하도록 추가 기능을 제공해 그 효율이 극대화되도록 하는 경우가 대부분인 것 같습니다. (GCP - airflow, kubeflow 제공, Databricks/Azure - MLflow 제공, Prefect - 자체 클라우드 서비스 … ) 해당 플랫폼을 사용한다면 좋은 선택지가 될 수도 있지만.. 경험상 이를 사내 환경에 직접 구축해 사용하려 하면 크고 작은 이슈들을 맞이하게 됩니다.
이런 MLOps 툴들의 소개글에는 거의 빠짐없이 Hidden Technical Debt in ML System (NIPS 2015, Google) 의 내용들이 등장 합니다. ML이 이제 학문 단계를 넘어서 실무 단계까지 넘어 왔고 (real-world ML system), 여기서 발생하는 부채 (debt)를 어떻게 경감시킬 수 있는지에 대한 고민들이 많아지고 있는 단계이기 때문에 MLOps 툴들도 계속 성장하고 있는게 아닌가 싶습니다.
Comments